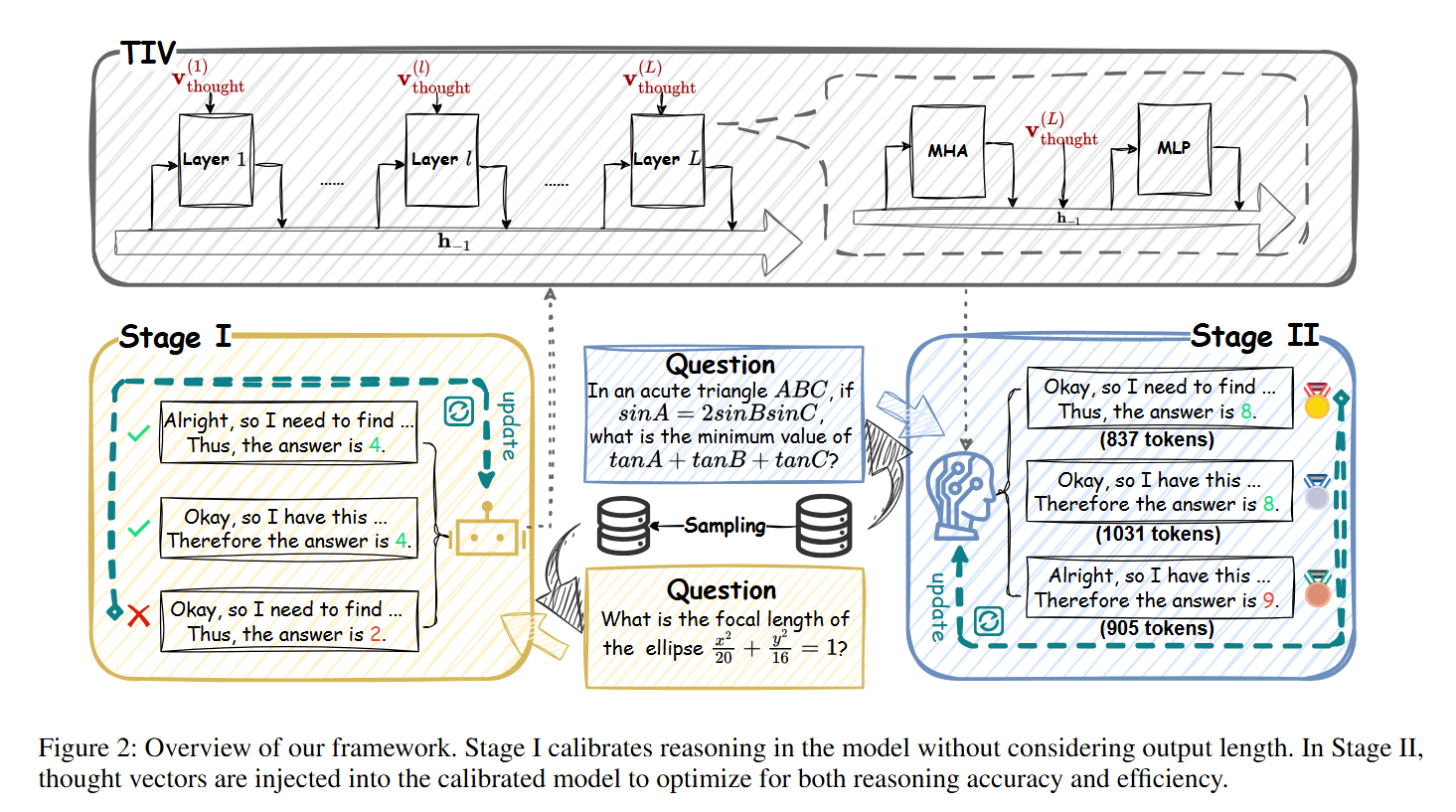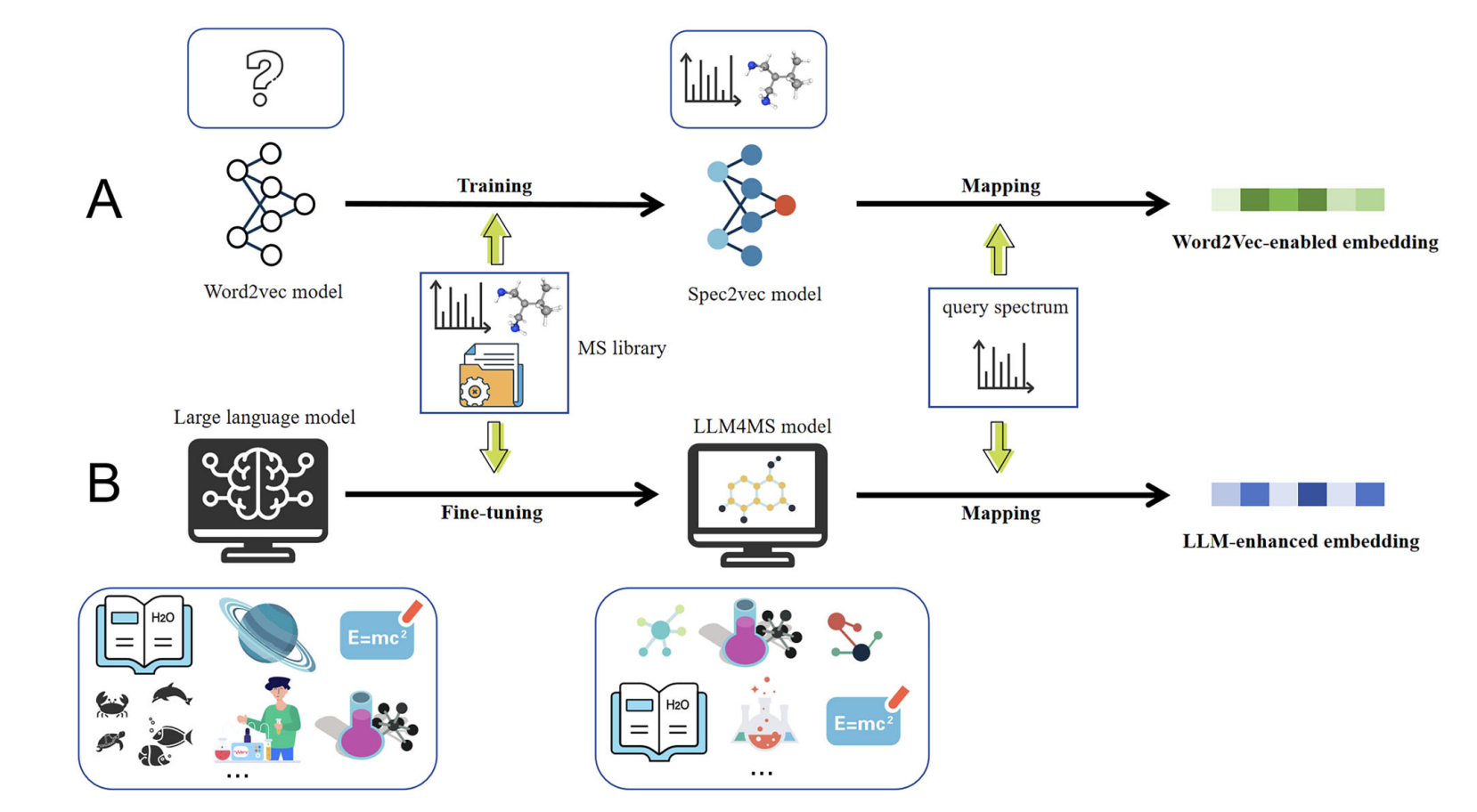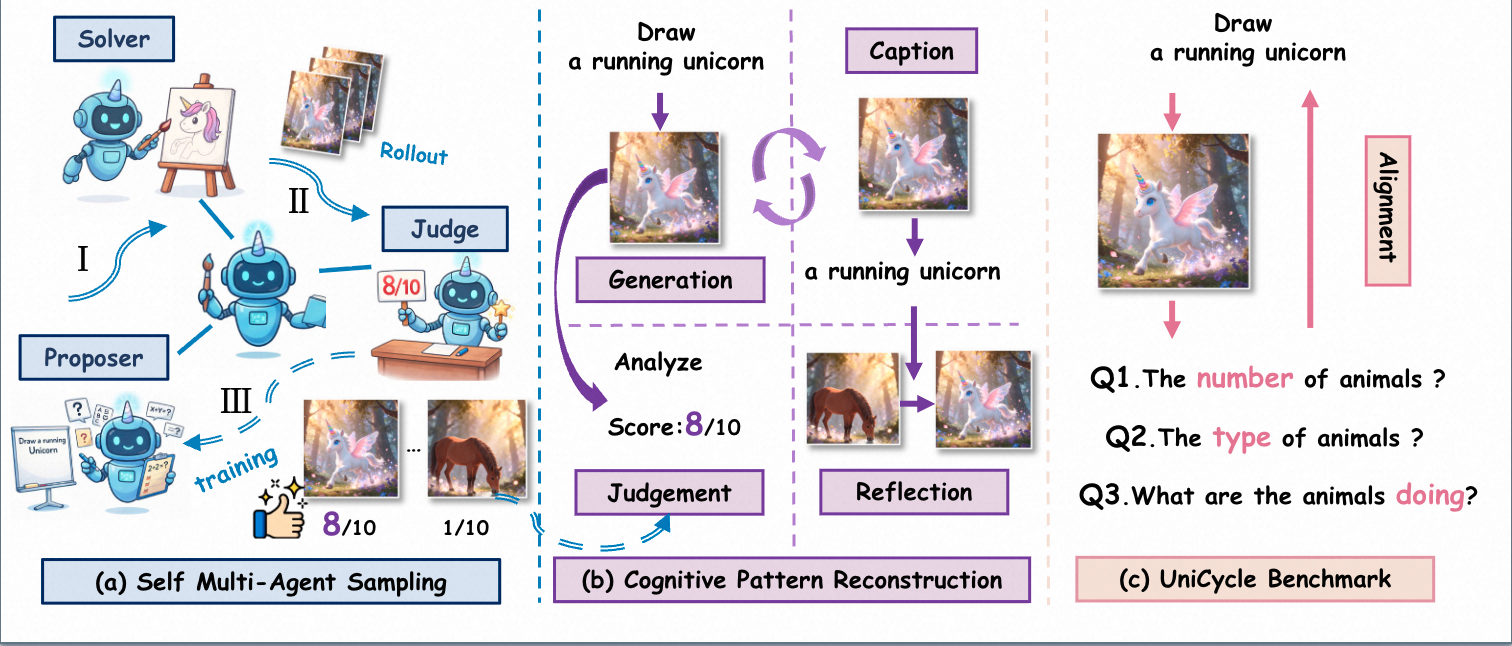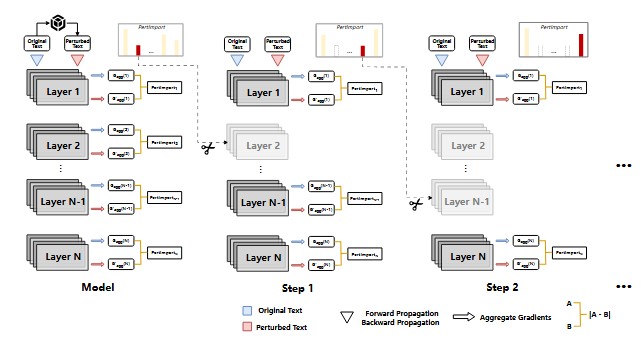
PIP: Perturbation-based Iterative Pruning for Large Language Models
We propose PIP (Perturbation-based Iterative Pruning), a method that iteratively prunes parameters based on the distinction between unperturbed and perturbed views. Experimental results show that PIP reduces parameter count by approximately 20% while retaining over 85% of the original accuracy.